Algorithmic Trading in the Vibe Coding Era
Source: Austin Hervias
For a long time, algorithmic trading was an exclusive investment strategy, mainly accessible to those with advanced programming skills or connections to elite financial institutions. The ability to build and deploy stock-picking algorithms was largely confined to computer scientists and Wall Street specialists with resources to spend and the human capital to create.
Over time, however, automated trading has moved into the financial mainstream. Investors have increasingly allocated capital to systematic strategies. Algorithms now execute a majority of trades in U.S. equity markets. The word “quant” has entered the vocabulary of every finance-oriented undergraduate.
But what does algorithmic trading actually look like in today’s investment firms? And with the rise of AI-powered coding tools, might everyday investors now be able to take advantage of automated trading strategies as well?
At its conceptual core, algorithmic trading is simple: give a computer rules, and have it execute trades without manual input. In practice, the range of sophistication is enormous. On the simpler end, a short Python script could buy a stock when its 50-day moving average crosses above its 200-day moving average and sell when the inverse occurs, a strategy which follows a basic momentum signal.
On the complex end, firms like Renaissance Technologies and Two Sigma run thousands of simultaneous models across global asset classes, drawing on unconventional data sources that most investors would never think to use or be able to access: satellite imagery tracking retail parking lot traffic, credit card transaction feeds, and natural language processing of earnings call transcripts.
Machine learning models can scan for patterns in market data that traditional statistical methods would miss entirely, while reinforcement learning systems optimize trade execution in real time.
Not long ago, retail investors who sought to utilize trading algorithms faced formidable barriers. Even for a strategy as simple as comparing moving averages, writing code that could connect directly to a brokerage was technically demanding, and reliable market data was expensive.
Today, those barriers have fallen almost entirely. AI coding assistants allow non-programmers to write functional trading scripts, and platforms like Alpaca offer free historical data and brokerage APIs for little to no cost. For clarification, an API (Application Programming Interface) is a set of rules and tools that allows two different software programs to talk to and exchange data with each other.
However, accessibility to these tools does not mean profitability. The market signals available to everyday investors have been scrutinized by professional quants for decades. In fact, even advanced techniques like machine learning software were in use as early as the 1980s. Whatever edge exists in publicly available market data is thin, and it's continuously being competed away by faster, better-resourced players. That’s why, for the average amateur investor, it is nearly impossible to write code that will consistently outperform the stock market.
However, the rise of prediction markets like Kalshi and Polymarket offers a new frontier where retail algorithmic traders may have a fighting chance. Compared to equity markets, prediction markets are young and thinly traded. Pricing inefficiencies are more common, and the competition is largely other retail participants rather than giants like Renaissance Technologies.
Institutional players have been slow to move into this space, in part due to regulatory uncertainty and in part because the markets are still too small to absorb the kind of capital that major funds deploy. For retail algorithmic traders, that lag may be precisely the opportunity.
Prediction markets, especially those susceptible to behavioral biases, often exhibit significant pricing inefficiencies that a sufficiently clever algorithm could exploit. One simple example is long-shot bias, a psychological tendency for traders to overpay for underdogs while undervaluing safer bets. This bias arises because the potential for a large payoff from an improbable event is often perceived as more exciting than the modest return from wagering on a favorite.
A 2007 study of bets placed in a prediction market tied to NFL games demonstrated this effect clearly:
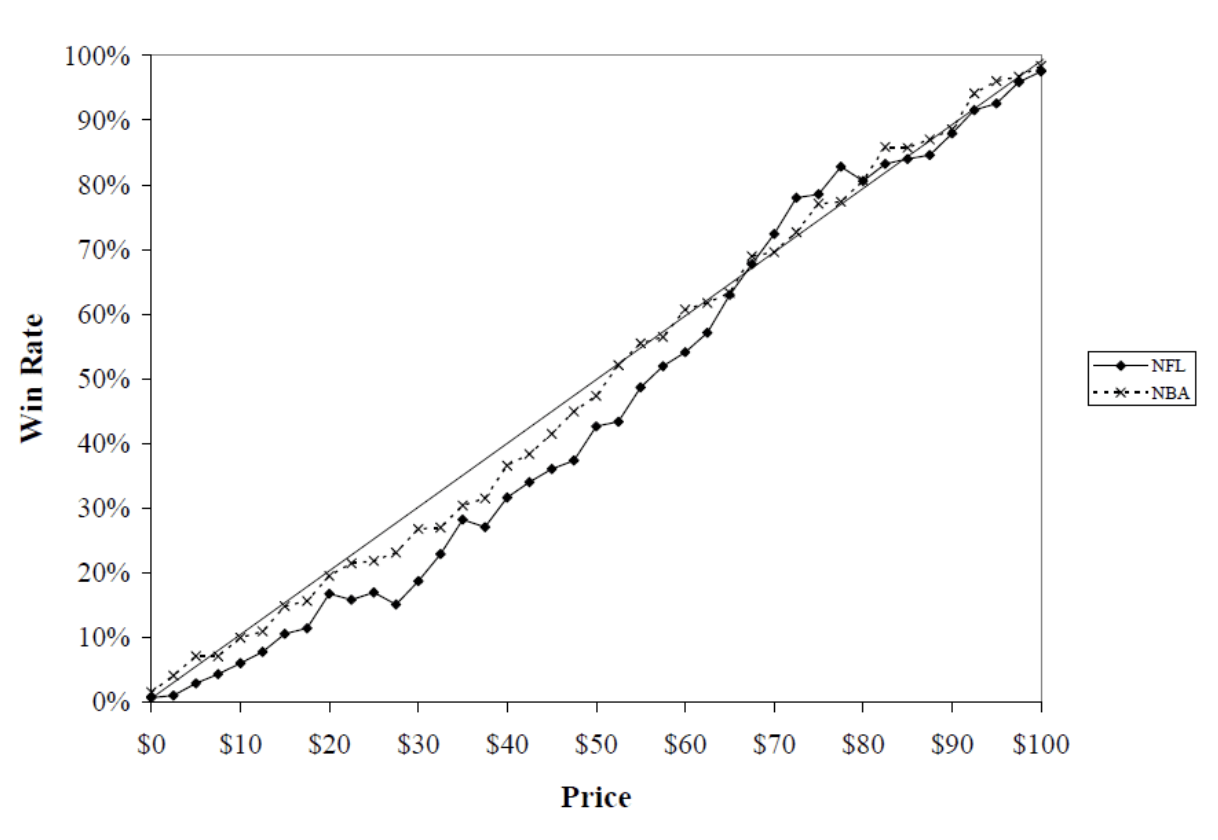
Source: Journal of Prediction Markets (2007)
According to the study, bets priced at a 70% or lower generally lost money, those priced between 70% and 85% generally made money, and bets priced above 85% approximately broke even.
Whether opportunities like this still persist is an open question. Since the study was conducted, prediction markets have grown substantially, attracting more participants and increasingly sophisticated traders. As these markets mature, simple behavioral biases are likely to become less common, and any remaining edges will grow thinner as competition erodes obvious inefficiencies.
Even so, the barriers to experimentation have never been lower. With modern APIs, accessible data, and Claude Code at our fingertips, testing algorithmic strategies is easier than ever, even if only as a way to explore ideas and better understand how markets behave.